The future is observable: seeing the forest and the log

From a buzzword tossed around engineering meetups in the early 2010s, it grew into a key aspect of operational resilience. The irony is, as our systems grew clearer, our conversations about observability seem increasingly murky. Teams are drowning in dashboards, metrics multiply like rabbits, and clarity fades. We’ve lost touch with what observability is about: it isn’t about endless monitoring — it’s about interpretation.

Early players created a market which is growing beyond them
The category emerged as cloud adoption was ramping up, along with microservices and distributed architectures, making traditional monitoring software obsolete given how complex the architecture became. In the early 2010s, companies like New Relic, Datadog or Elastic led market education and managed to popularize the concept, expanding the reach of “monitoring” from predefined metrics to more exploratory questions around logs, metrics and traces.
Today, we’re looking at hundreds of systems, with an ever-expanding volume of data flowing through. Post COVID, observability platforms saw data volume triple, AI became the subject matter, fuelling the demand for observability platforms, and spicing up the bill for customers as well.
Both stateless and stateful observability are today used, by different types of businesses.
- Stateless observability is cost-effective and suited for simpler systems, offering basic real-time monitoring without historical context. No correlation is made between past and future events, so each telemetry signal is evaluated in isolation.
- Stateful observability, while more expensive, provides deeper insights by retaining and analysing data over time — ideal for complex, distributed environments. Smaller teams benefit from stateless tools, while enterprises need the richer context of stateful solutions to ensure reliability at scale.
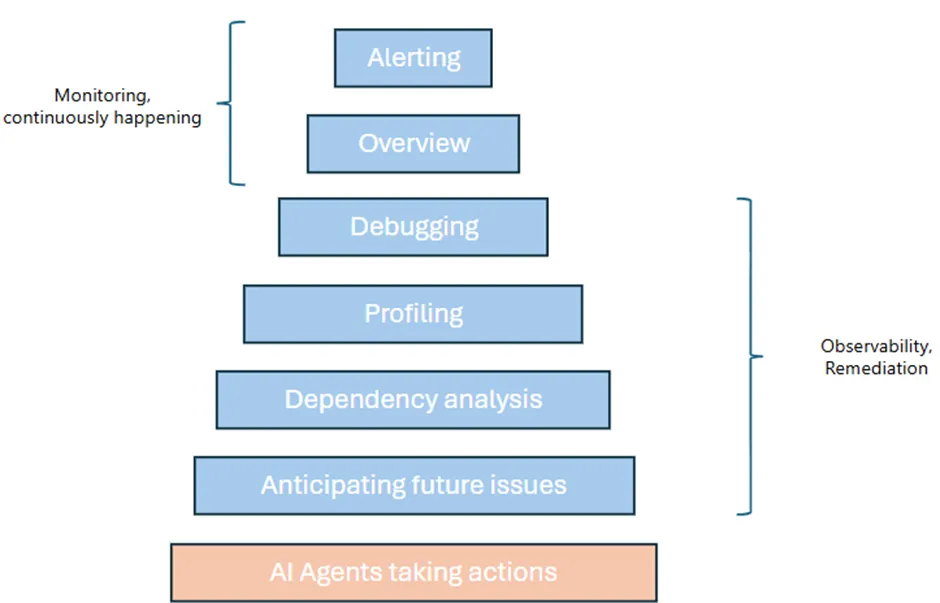
What are observability’s key principles?
Observability is about understanding a system’s behaviour and internal state by analysing outputs (telemetry data) such as logs, metrics and traces. Here are the core principles behind observability:
- Comprehensive Data Collection: Gathering complete telemetry — logs, metrics, traces, and events — to achieve full visibility into system behaviour.
- Real-time Monitoring: Continuously tracking system health to rapidly detect and respond to issues as they occur.
- Correlation and Contextual Analysis: Linking related data points from diverse sources to quickly uncover causal relationships and root causes.
- User-centric Insights: Prioritizing insights that directly impact user experience and business outcomes, such as performance bottlenecks or anomalies.
- Automation and Scalability: Utilizing AI-driven anomaly detection and automated data processing to scale observability with growing complexity and data volume. AI agents are starting to address this part of the workflow specifically.
There is not a single user for observability platforms
The user base for observability platforms is quite broad, given how key it is for both business and engineering teams, coming with different needs.
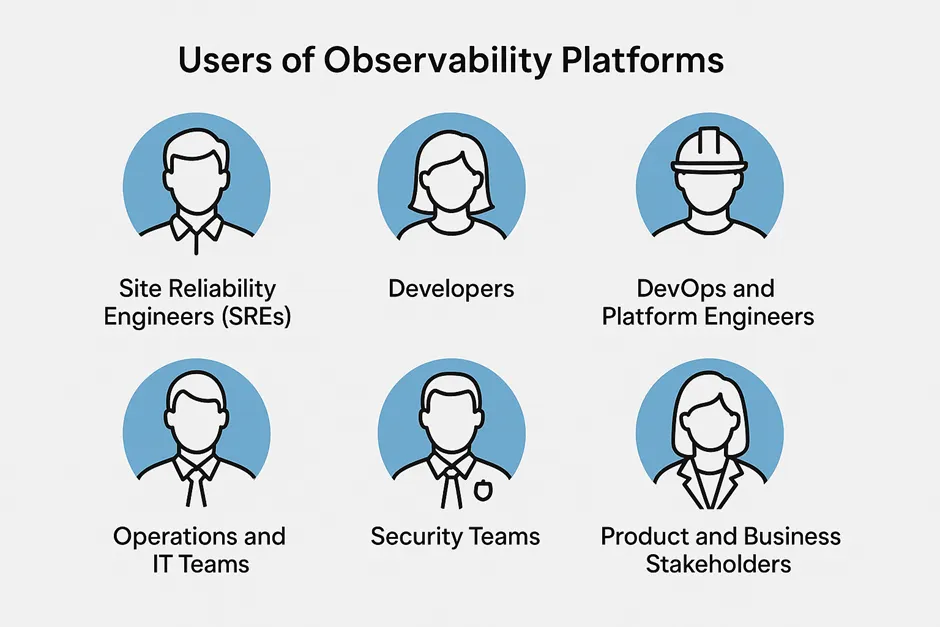
- Site Reliability Engineers (SREs) who need deep visibility to maintain uptime, detect incidents, and resolve issues quickly.
- Developers who use observability to debug code in production, trace requests, and understand system behaviour under load.
- DevOps and Platform Engineers who integrate observability tools into CI/CD pipelines and infrastructure to ensure smooth deployments and operations.
- Operations and IT Teams who monitor infrastructure health and ensure service-level objectives (SLOs) are met.
- Security Teams who analyse logs and telemetry for anomalies that might indicate security incidents.
- Product and Business Stakeholders who look for insights into how system performance impacts user experience and business outcomes.
The landscape is growing with the market, which shows no sign of slowing down
The observability market remains very fragmented, with large businesses emerging in this category. The largest ones, now incumbents, being Datadog, New Relic, Splunk, Elastic and Grafana. The market has been growing steadily, and so did those players, with Datadog, Elastic and Splunk (all billion dollar businesses) growing at a similar pace, of around 20–25% YoY. Those players charge based on the volume of data flowing through the platform, leading enterprises to allocate a large part of their cloud cost to observability.
Given the high price tags — 10%+ of cloud spend and sometimes reaching up to $100 million annually — some enterprises have attempted to build their own observability stack. However, the engineering investment, depth of functionality, and ongoing maintenance make this a viable option only for a few. Datadog, widely regarded as the easiest and most comprehensive to deploy, is also the most expensive, which has led many customers to limit data ingestion to manage costs. This reinforces a growing industry consensus: effective observability doesn’t require collecting 100% of logs.
Newcomers were increasingly competing in this market… even before AI
Cribl, PagerDuty and BigPanda have all reached scale with product that help better manage data pipelines, incident management, root cause analysis… Others like Grepr have tried to reduce the bill for customers, but are yet to get significant market share.
We believe that the AI wave will bring even more complexity to how developers (and AI agents) interact with software infrastructure, coupled with an increasing cloud bill, opening the door for more new players to emerge and get market shares out of existing players.
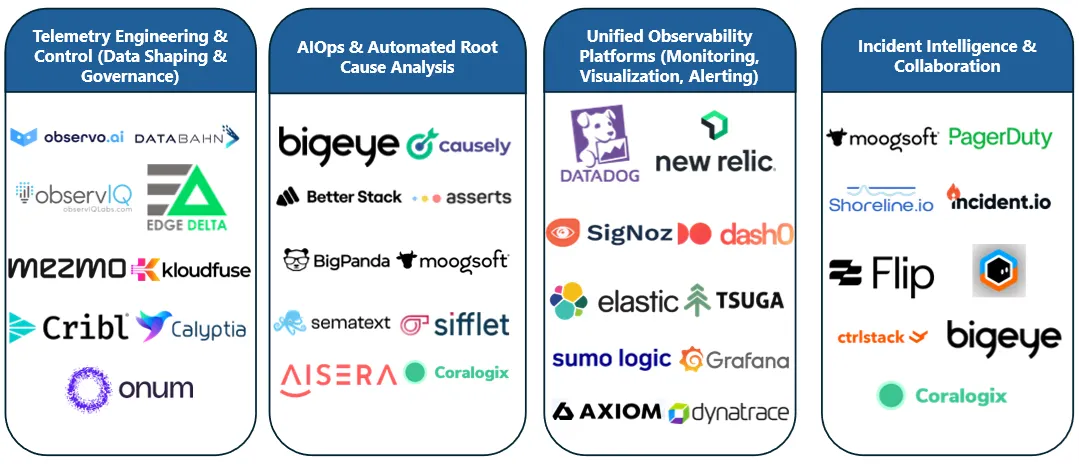
There are billions of revenue spend up for grabs
We believe that over the next few years, observability will evolve from a siloed monitoring function to a deeply integrated business intelligence, likely coupled with an automation layer, powered by AI agents.
Traditional tools like Datadog and New Relic have strong moats but are increasingly scrutinized for cost and limited actionable insight. The rise of OpenTelemetry and standardization has democratized data collection, diminishing legacy vendor lock-in and enabling a wave of new entrants. Meanwhile, enterprises crave platforms that do more than ingest data — they seek solutions that offer intelligent, AI-powered correlation, predictive diagnostics, and decision support across increasingly complex, cloud-native infrastructures. This creates a window for startups to build vertically integrated or domain-specific observability platforms with rich UX, better developer velocity, and automated root-cause analysis.
As observability becomes tied to business outcomes — via integrations with ERP, CRM, or custom app layers — the value shifts from raw telemetry to contextual insights. The future lies in platforms that not only detect but also help resolve issues, reduce MTTR (Mean Time To Respond), and close the loop through AI agents. Pricing models, UI innovation, and integration capabilities will be critical differentiators.
In short, the next generation of observability startups will not merely compete on features — they will redefine the experience and economics of how systems are understood and managed.
At Illuminate Financial, we believe we’re still at the beginning of the Observability 2.0 wave and are convinced of its long-term potential. We would love to chat if you’re building in this space.