The Primitive to Scale the Next Billion Agents: the Path to Agent-native clouds

Introduction
The trillion dollar question: Do we have the infrastructure to deploy and scale the next Billion agents?
Startups and enterprises are building and adopting agents at scale. Every human could soon use an agent, and every agent could create more agents. The number of people online has compounded from about 300 million users in 1999 to nearly 6 billion in 2025. Soon, every piece of software we touch will have agents assisting or running in the background.
The number of agents that emerge will be huge: (human)^ (agents)^n.
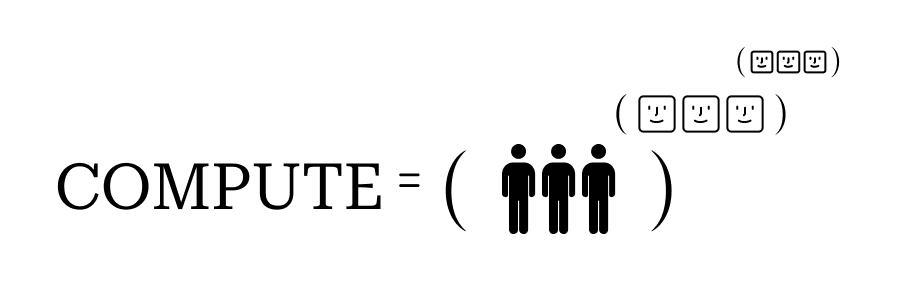
The compute required to power these agents will dwarf today’s workloads. Agents don’t just automate workflows. They respond intelligently, interact across systems, and use tools to achieve goals. More interestingly, we’re witnessing new compute patterns emerge — agents can branch, parallelize, and explore multiple paths simultaneously.
Our hypothesis: we will require an entirely different runtime environment for agentic workloads
Agents demand fast, stateful, and branchable runtimes. Hyperscalers weren’t built for this pattern. We’re excited about the Agent Sandbox: the bridge between agents and the cloud, or as we call it, “the point of most optimal consumption”.

We’ll explore:
- A simplified history of cloud infrastructure
- The problem with today’s cloud model
- The primitive of agent-native clouds
- The path to alternative/neo clouds
A Brief History of Cloud Infrastructure
Before diving into neoclouds, it’s worth revisiting the primitives that shaped today’s infrastructure:
- VMware and the rise of virtualization: around 1999, VMware commercialized virtual machines (VMs). Virtualization allowed hardware resources of a physical computer (e.g. CPU, memory, storage) to be sliced into multiple “virtual computers” each with its own operating system. This was critical in solving the pervasive hardware underutilization problem.

- AWS: in the late 2000s, Amazon Web Services launched and laid the foundation to public cloud infrastructure with products such as EC2 (Elastic Compute Cloud). These were “virtual servers as a service”, allowing customers to rent dedicated cloud servers, configure specifications like (CPU, RAM, storage), and were billed per-hour. AWS continued to expand into hundreds of cloud services, and developers adopted a new pattern of development — becoming “cloud native”.
- Containers & Orchestration: before containers, apps were tightly bound to the specific environments they were deployed in — in other words, if you moved the same codebase to a different server it may fail to run. Containers enabled portability for software where no matter where the code is executed, from the laptop, staging/testing servers, and production servers. Docker simplified working with containers and along with their introduction of “images”, ensured reproducible builds and rapid deployment. Meanwhile Kubernetes served as an orchestrator which could manage hundreds or thousands of Docker containers.
- Serverless computing: in the mid 2010s, serverless computing started to become mainstream. Developers can focus on running code or applications without provisioning or managing any infrastructure, and cloud providers would decide how to scale with load. AWS launched Lambda (for short-lived event-driven functions) and Fargate (for running containers without managing servers). Today, we even have abstractions like Vercel to simplify this further.
The problem with existing cloud infrastructure
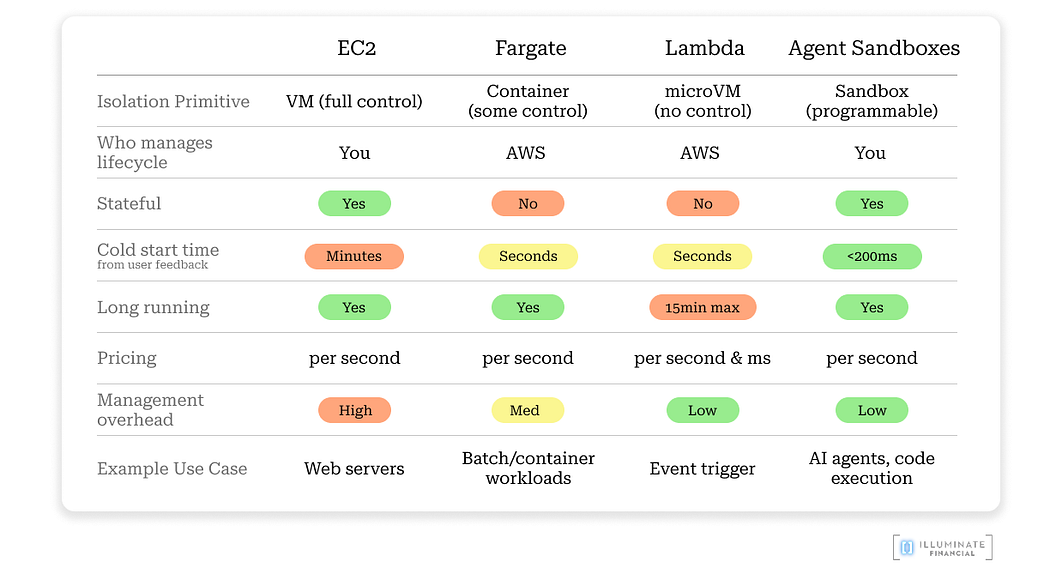
After conversations with startups, one theme stands out: today’s cloud infrastructure is not purpose-built for agent workloads. Hyper scalers struggle on three dimensions: speed, state, and cost. Cloud setup now slows more teams than it accelerates them.
- Speed: EC2 takes minutes to start and Fargate takes seconds, while agents need near instant spin-ups — not minutes — to stay responsive. These slow cold starts and initialization overhead will compound rapidly at scale, especially with branching and parallelization (explored further below).
- State: Lambda and Fargate reset environments after each execution, and persistent storage options add latency. Re-loading large codebases or dependencies slows startup-to-action times significantly. Agents need persistent environments (apps, disk, memory, and kernel) that can resume instantly.
- Cost: Cloud billing models (EC2, Fargate) are optimized for predictable or sustained utilization, but struggle with bursty workloads. EC2 and Fargate bills per second with 1min minimum, but for workloads that start/stop rapidly, minimum billing windows are not efficient. Further, initialization and idle times add an invisible cost overhead as you scale. Meanwhile, serverless is cheap for short bursts but sustained workloads become expensive. Agents have dynamic workloads, which could last milliseconds or hours, depending on the task. Lastly, managing EC2 instances requires lots of management overhead, which are people costs.
The primitive of an Agent-native cloud
Agentic Sandboxes
The agentic sandbox is a purpose-built runtime. It’s fast, stateful, isolated, cost-optimized, and comes pre-packaged with agent tools. Think of the runtime as a “theatre” for a play: same lighting, stage, and props, so the play runs the same way every time.
We’re seeing the earliest signs of a platform shift: startups are increasingly choosing agentic sandbox providers as their cloud, the new substrate for agentic software deployment.

We’ll explore why agents need such a specialized environment.
What cloud infrastructure do agents need?
- Speed: Agents need to spin up instances almost instantly to deliver a seamless, interactive experience. <200ms spin-ups are the benchmark. Think of your interactions with Claude, ChatGPT, or Manus. You expect responses immediately, not seconds or minutes of delay. At the same time, these instances should shut down the moment an agent completes its task to minimize wasted compute time and cost.
- Statefulness: persistent file systems, memory, and processes between sessions (like reopening your laptop with every window still open). You don’t need to reinstall applications or reinstall any dependencies.
- Built-in Tooling: CLI, browser, git, and other tools pre-installed, ideally as headless, agent-native utilities to reduce overhead.
Press enter or click to view image in full size

- Cost efficiency: you pay only while agents are running. Any idle resources are terminated instantly.
- Observability and Security built-in: fine-grained controls define what agents can access, and every action is logged. The sandbox state provides granularity to what has happened in environment, which makes it reproducible.
- Isolated Environment: each sandbox contains failures and a misbehaving agent can’t bring down the system. State also unlocks the ability to roll back to a previous snapshot.
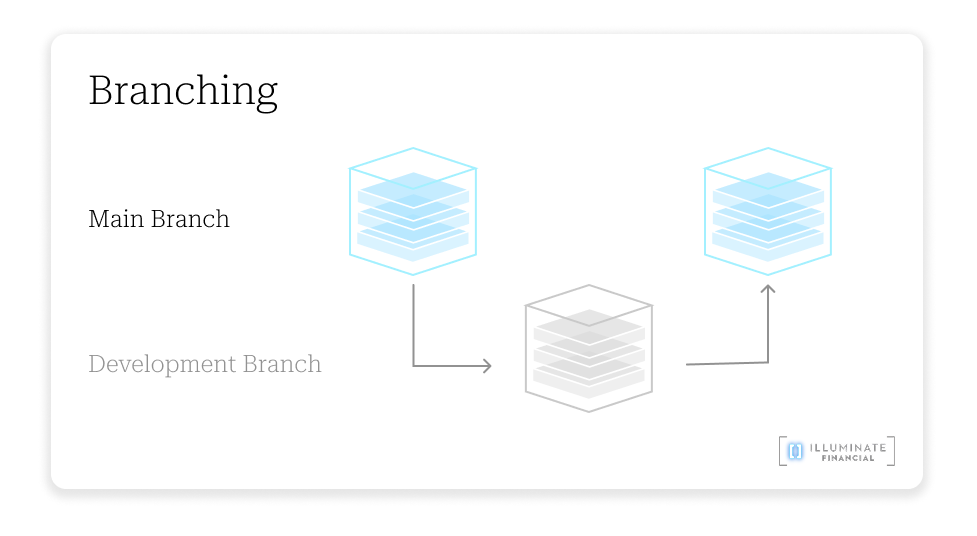
- Branching: while currently a niche pattern, branching allows agents to spin up VMs in in parallel to run at multiple decisions at once.
What does this unlock?
With the combination of state and speed, amongst the other benefits above, these unlock interesting use cases.
- Fast, stateful, coding agents: if you’re running large/multiple code repositories for a coding agent (like Devin), with an agentic sandbox, you’re able to store the repo on the disk, along with all the dependencies and libraries installed.

- Debugging: sandboxes can record the complete path execution — from DOM state, network requests, model outputs. This is highly effective for reproducibility. Subsequently, for debugging, agents can explore alternative simultaneous pathways to solve an issue rather than start/stop/restart in sequence.
- Browser-based agents: agents that interact with web pages, like a research agent that navigates/summarizes websites or workflow agents that perform tasks in SaaS apps would benefit from full policy controls and horizontal scalability.
- Parallelization: have you ever been stuck between two choices and had to make a single decision? With parallelization, it allows agents to “branch”, in other words, explore the futures of what multiple pathways may lead to, then return to the main branch after finding an answer. This is only possible when you can turn on new sandboxes quickly, store the state of each sandbox, and turn off sandboxes in rapid succession as you get an answer.

- Reinforcement Learning: large language models are pre-trained with billions/trillions of parameters which takes thousands of GPUs, and weeks/months to train. However, with parallelization, you can spin up thousands of sandboxes to run reinforcement learning on a foundation model, enabling high efficacy of smaller models at a lower cost.
Why this could be “exponentially explosive”
Programming could shift from sequential execution to parallel exploration. Instead of one engineer solving a problem line by line, thousands of agents will pursue parallel branches and converge on solutions.
If this is adopted, the effect is exponential. Problems will be solved faster and software development could be driven by “agentic swarms”. Which is why we’re excited about the infrastructure that can support billions of agents.

The path to alternative/neo clouds
The “physics of shipping” have changed — companies are being built at 15,000 RPM. Startups are moving from ideation to execution to days, or even hours, but existing cloud providers are too complex to figure out, and insufficient in providing the capabilities that agent-native companies need. Companies have a high willingness to pay for speed and convenience, and as a result, positions alternative cloud providers to thrive.
The new ecosystem for agent-native clouds
The agentic sandbox is the first layer of the agent-native cloud, but there are probably more capabilities to be explored deeper in each of its vectors: storage, networking, controls (policy, identity, safety), observability, and tooling. The best-of-breed for each of these vectors might emerge.
Ultimately, these will all contribute to a new ecosystem of cloud infrastructure for agents to scale on. We’re excited about what this ecosystem could look like, and this article is just the beginning.
Toward an Agent-defined Cloud?
VMware popularized the software-defined data center. What if we imagined the next step: an agent defined cloud, where compute, storage, networking, and polices can all be provisioned in a single prompt?
Infrastructure becomes self-describing, self-provisioning, and self-optimizing… not by humans, but by agents.
That will be interesting.
